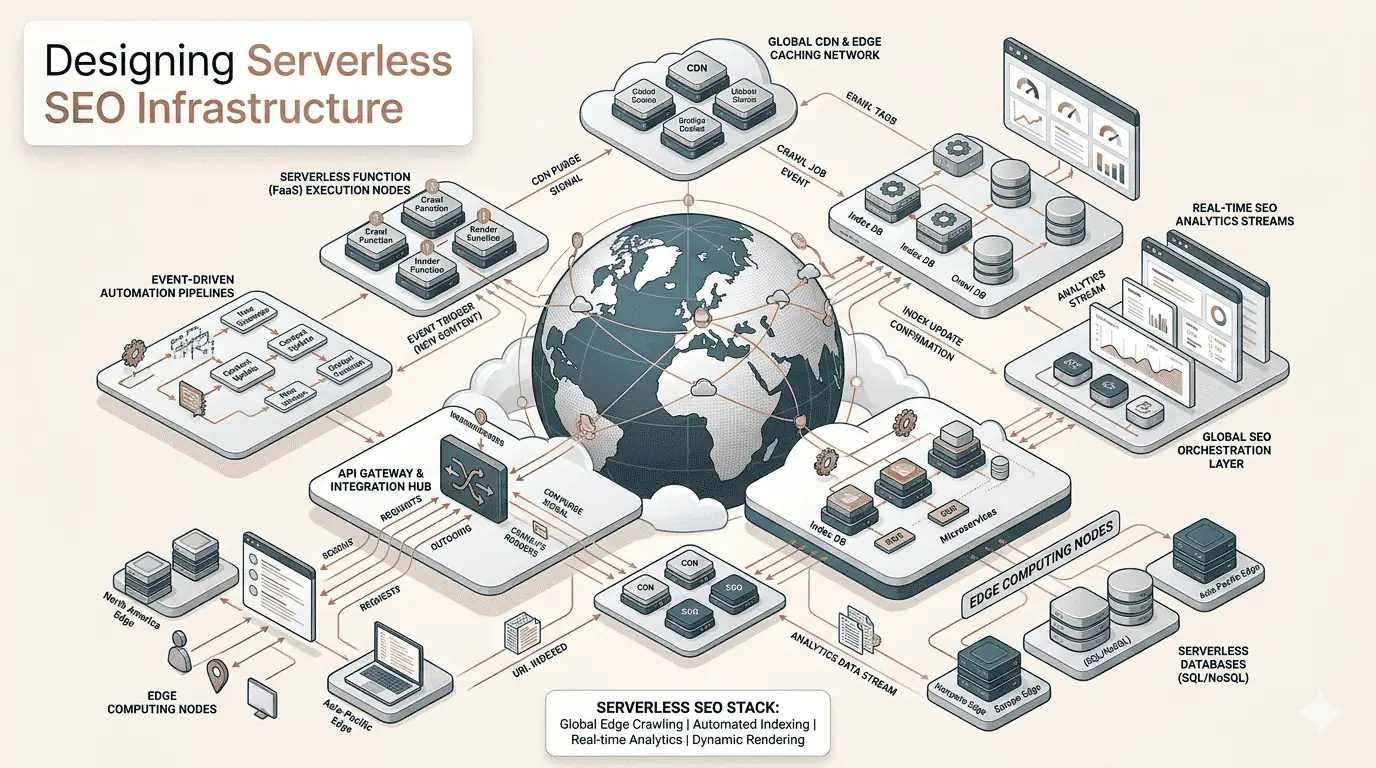
Running SEO tooling at scale requires a different architectural approach than a typical web application. Crawlers, audit queues, indexing pipelines, and real-time monitoring all have distinct compute, latency, and reliability requirements — and serverless edge infrastructure maps to these requirements well. Here's what we learned building SEOVentra on this stack.
Why edge-first for SEO tooling?
The case for edge deployment in SEO infrastructure comes down to three requirements: global latency for crawl requests, burst compute for queue processing, and zero cold-start tolerance for monitoring alerts.
- →Crawl requests benefit from sending from geographically distributed sources — edge workers enable this natively
- →Indexing queues need to process submission bursts without over-provisioning dedicated servers
- →Alert webhooks need sub-second dispatch with high reliability — edge cold start times of 0ms make this possible
The core architecture
- 01Cloudflare Workers — API routing, queue dispatch, real-time webhook delivery
- 02Cloudflare Durable Objects — stateful crawl sessions, rate limit tracking, queue coordination
- 03Cloudflare D1 — structured data storage for audit results, URL status, analytics
Traditional server infrastructure requires capacity planning for peak load, complex auto-scaling, and per-region deployments for acceptable global latency. Edge-first eliminates all three at the cost of a different programming model.
Handling crawl workloads
Technical SEO audits require fetching pages, parsing HTML, checking resources, validating schema markup, and computing scores — CPU-intensive work that doesn't map naturally to edge workers with tight compute limits. The pattern that works: edge workers handle request intake and result serving; heavier crawl computation runs on Workers with extended CPU allowances or offloads to R2-backed batch jobs.
See what crawlers actually see on your pages
One of the tools we've productised from our own infrastructure is the Crawler Simulator. It lets you see any page exactly the way Googlebot sees it — rendered HTML, resolved robots directives, discovered links, and indexation signals.
See your pages the way search engine crawlers do — analyzing crawlability, rendering, directives, links, and indexation signals. Reveals crawl issues invisible to browser DevTools.
Queue architecture for indexing pipelines
- 01High priority — new content submitted by the user's webhook or API call
- 02Normal priority — scheduled re-validation of previously indexed URLs
- 03Low priority — bulk sitemap processing and historical crawl backfill
Observability at edge scale
interface LogEvent {
timestamp: number;
level: 'info' | 'warn' | 'error';
event: string;
siteId?: string;
urlCount?: number;
durationMs?: number;
}
function log(event: LogEvent, env: Env) {
env.ANALYTICS.writeDataPoint({
blobs: [event.event, event.level, event.siteId ?? ''],
doubles: [event.durationMs ?? 0, event.urlCount ?? 0],
indexes: [event.siteId ?? 'global'],
});
}What we learned
- →Durable Objects are the right primitive for stateful coordination — but require careful design upfront
- →D1's SQLite-at-edge constraint means query patterns need to be simple — avoid complex joins under load
- →Workers' CPU limit pushes heavy computation into queue-based patterns naturally
- →Zero cold starts are worth the architectural complexity — alert delivery latency went from 800ms to under 120ms
- →Testing Workers locally with Miniflare is fast enough that the development cycle isn't painful
Generate SEO-friendly robots.txt files with custom crawl and indexing directives — useful when configuring which paths your edge infrastructure should and shouldn't expose to crawlers.
Co-founder and CTO of SEOVentra. Builds the indexing pipelines, audit engine, and AI visibility infrastructure. Former backend engineer obsessed with making search work at scale.